
Valor de la Celda Anterior y Siguiente con Lenguaje DAX
Este artículo hace parte de la iniciativa de las Recetas DAX, una idea que hemos tenido en el tintero por años, pero que trabajaremos este 2020 para que sea una historia diferente.
— TABLA DE CONTENIDO DE ESTE ARTÍCULO
1. Valores Adyacentes en Columnas Calculadas en DAX
a. Valor Celda Anterior
b. Valor Celda Siguiente
c. Valor n Celdas Anteriores o Posteriores
Bienvenido a un nuevo artículo, sino tienes ideas de qué van las recetas DAX, el principio rector es:
Crear fórmulas preconstruidas listas para utilizar, de escenarios comunes que las personas pueden necesitar sin necesidad de saber una sola línea de lenguaje DAX
Porque …
La única manera de sacarle 100% provecho a Power BI y Power Pivot es siendo un Magíster en el lenguaje DAX
… O utilizar las Recetas DAX
Como es típico de nuestros vídeos, artículos y demás, el problema del día de hoy viene de una pregunta planteada en uno de nuestros entrenamientos, en esta ocasión, por parte de José en una capacitación presencial.
Valores Adyacentes en Columnas Calculadas
Obtener el valor de una celda adyacente, es decir: la celda siguiente o anterior; la celda de la derecha o de la izquierda en Excel es extremadamente fácil e intuitivo.
El motivo es porque la interfaz de Excel tiene características intrínsecas que permite identificar cada fila en toda la hoja de cálculo de manera única, con esto me refiero al indicador de fila de la interfaz, que de hecho, identifica con número consecutivos empezando desde el 1:
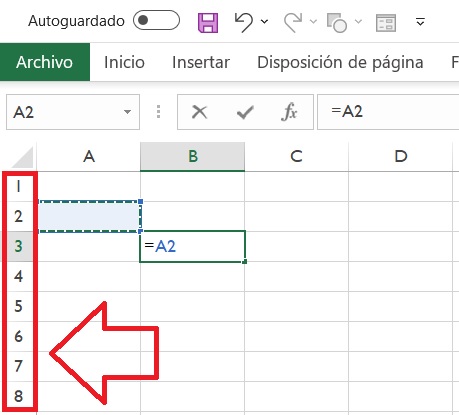
Indicador de Fila en Excel
Con las columnas el relato va casi igual, pero se diferencia en que las identifica con letras consecutivas (A, B, C, …), así:
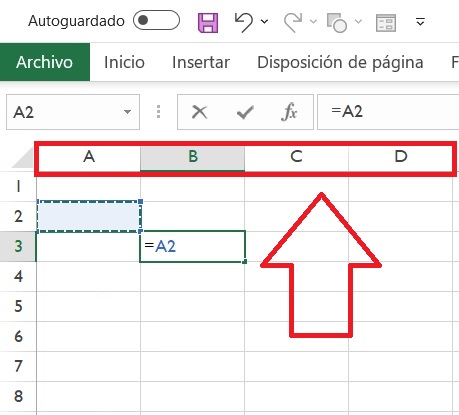
Identificador de Columna en Excel
Esto dota a Excel una gran facilidad para identificar de forma única e inequívoca valores no sólo de celdas adyacentes sino en cualquier parte de la hoja de cálculo.
Situación diferente en DAX.
Si bien en DAX podemos identificar cada columna certeramente gracias a que su sintaxis viene equipada para eso, que sería algo así:
=
Pedidos[SKU]
Por el lado de las filas carece completamente de algo mediantemente similar, y esto hace que no sea evidente poder extraer valores de casillas adyacentes, es más le confiere a dicha tarea tintes de complejidad y sobre todo impacto en el rendimiento del modelo en el eje negativo de la escala.
Por lo que, de alguna manera, debemos añadir algo que identifique de manera única cada registro en una tabla de datos.
Podríamos pensar en una llave o una llave primaria que ya tenga nuestra tabla, sin embargo, esto puede hacer aún más compleja la expresión DAX porque no necesariamente los identificadores van a ser consecutivos, y esto es lo que necesitamos para emular esa característica de Excel.
Por, lo tanto, añadir una columna de índice con Power Query sería lo recomendable.
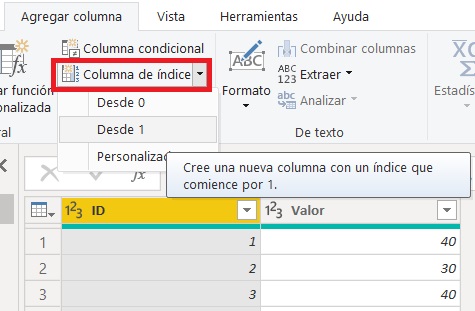
Teniendo un identificador único y consecutivo ya podemos valernos de los contextos de fila para alcanzar el objetivo.
El detalle técnico de porque funciona no lo explicaré, puesto que la meta es compartir fórmulas de tipo copy/paste que puedas utilizar.
Para todos los detalles internos: Énfasis en Fundamentación y Contexto de Evaluación.
Valor Casilla Anterior
Supongamos que nuestra tabla se ha de denominada de manera muy creativa: Tabla, y nuestra columna de índice le dejamos el nombre ID, además, la columna donde queremos extraer el valor previo se llama Valor:
Celda Anterior =
VAR ValorActual = Tabla[ID]RETURN
SUMX ( Tabla; IF ( Tabla[ID] = ValorActual – 1; Tabla[Valor]; BLANK () ) )
Valor Casilla Siguiente
Siguiendo la misma notación de nombres, para extraer el valor de la casilla siguiente tendríamos la siguiente expresión DAX para una columna calculada:
Celda Siguiente =
VAR ValorActual = Tabla[ID]RETURN
SUMX ( Tabla; IF ( Tabla[ID] = ValorActual + 1; Tabla[Valor]; BLANK () ) )
Valor n Celdas Anteriores o Posteriores
De este escenario también deriva que no necesariamente queremos el valor de la celda inmediatamente anterior o posterior, sino tal vez una casilla dos o más puestos adelante (o atrás).
Con las expresiones previas podemos extrapolar, es decir, si queremos que sea una celda anterior vemos que el número es negativo, y al ser el número 1 asociado al valor anterior podemos incrementar el valor en el número de posiciones que nos queremos mover, por lo tanto, si lo agregamos en una variable, nuestra receta DAX quedaría:
n Celdas Anteriores =
VAR ValorActual = Tabla[ID]VAR NumPuestosPrevios = 2
RETURN
SUMX (
Tabla;
IF ( Tabla[ID] = ValorActual – NumPuestosPrevios; Tabla[Valor]; BLANK () )
)
Para el caso de que sean posteriores, la expresión y lógica es la misma, sólo que cambia la operación a una suma:
n Celdas Posteriores =
VAR ValorActual = Tabla[ID]
VAR NumPuestosPosteriores = 3
RETURN
SUMX (
Tabla;
IF ( Tabla[ID] = ValorActual – NumPuestosPosteriores; Tabla[Valor]; BLANK () )
)
Yo la verdad no recomiendo ejecutar estas expresiones si la cardinalidad de la tabla es medianamente alta (200 mil registros en adelante), puesto que si se llega a requiere caculos de este estilo, la primera opción es determinarlos en el origen, y sino el plan B sería en Power Query que un poco mejor (en el próximo artículo expongo como sería con lenguaje M), pero si requerimos para algo muy concreto y no tenemos de otra, esta opción se debe implementar con muchísimo cuidado.
Extraer valores adyacentes con medidas tiene un poco más de complejidad en las expresiones, por lo que lo dejaremos para otra receta.
Eso es todo por esta receta DAX.
— Miguel Caballero


